Dobry wykres jest wart więcej niż tabela z setkami liczb. W tej sekcji nauczymy się tworzyć cztery najważniejsze typy wykresów w analizie ekonomicznej.
Oba środowiska (R/Python) mają swoje podejście do tworzenia wykresów:
R / ggplot2 — opiera się na gramatyce wykresów (Grammar of Graphics ). Wykres budujesz warstwami: dane → geometria (linia, słupki, punkty) → skale → etykiety.Python / matplotlib + seaborn — seaborn to uproszczone API dla typowych wykresów statystycznych; matplotlib daje pełną kontrolę nad każdym detalem.
Wykres liniowy — szeregi czasowe
Idealny do danych ekonomicznych zmieniających się w czasie.
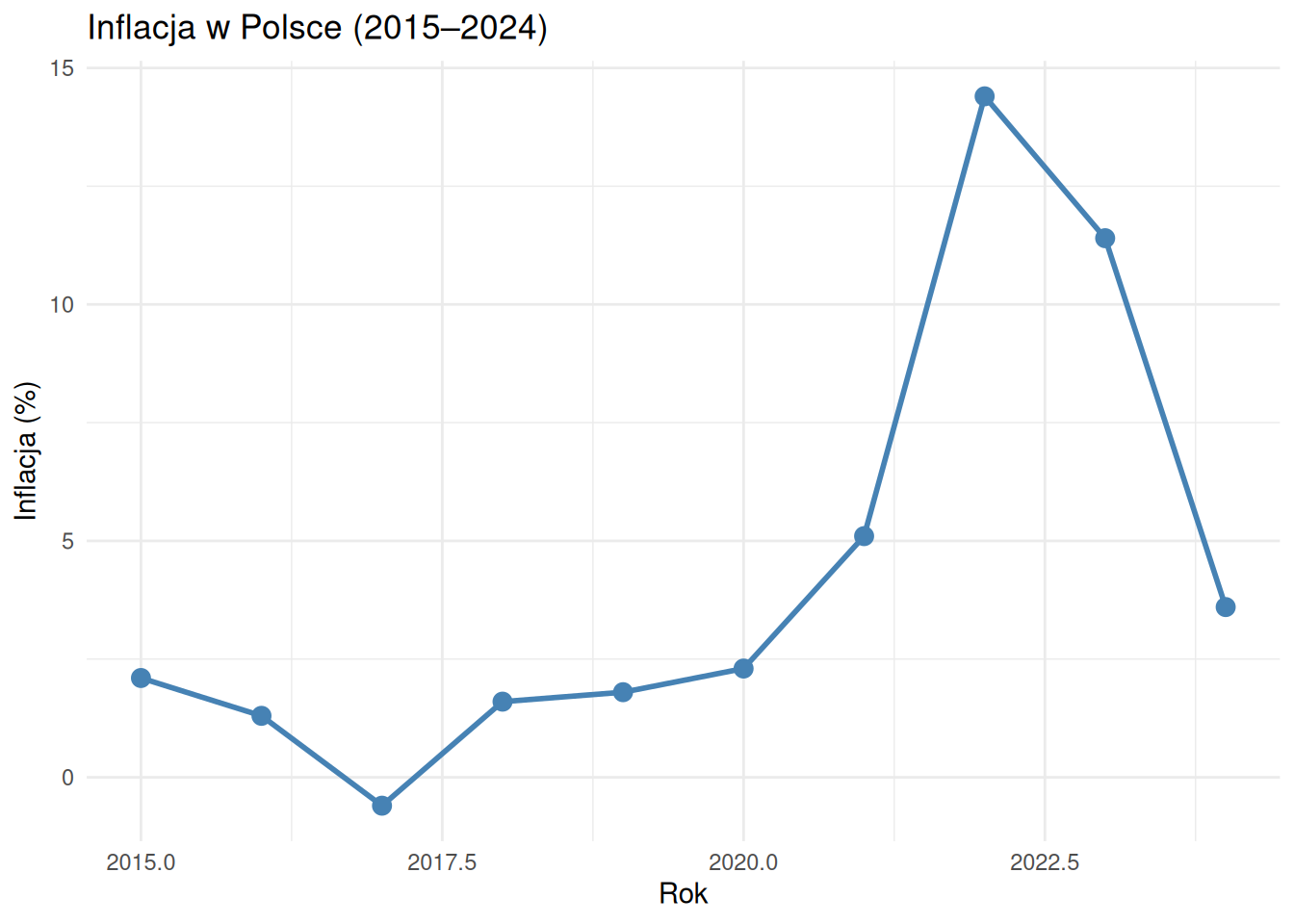
library (ggplot2)library (dplyr)<- data.frame (rok = 2015 : 2024 ,PKB = c (1800 , 1862 , 1984 , 2120 , 2292 , 2330 , 2625 , 2780 , 2900 , 3070 ),inflacja = c (2.1 , 1.3 , - 0.6 , 1.6 , 1.8 , 2.3 , 5.1 , 14.4 , 11.4 , 3.6 ),stopa_bezrob = c (7.5 , 6.2 , 5.5 , 4.9 , 3.8 , 3.3 , 5.6 , 3.4 , 2.9 , 2.8 )# Prosty wykres liniowy ggplot (dane_ekon, aes (x = rok, y = inflacja)) + geom_line (color = "steelblue" , linewidth = 1 ) + geom_point (color = "steelblue" , size = 3 ) + labs (title = "Inflacja w Polsce (2015–2024)" ,x = "Rok" ,y = "Inflacja (%)" + theme_minimal ()
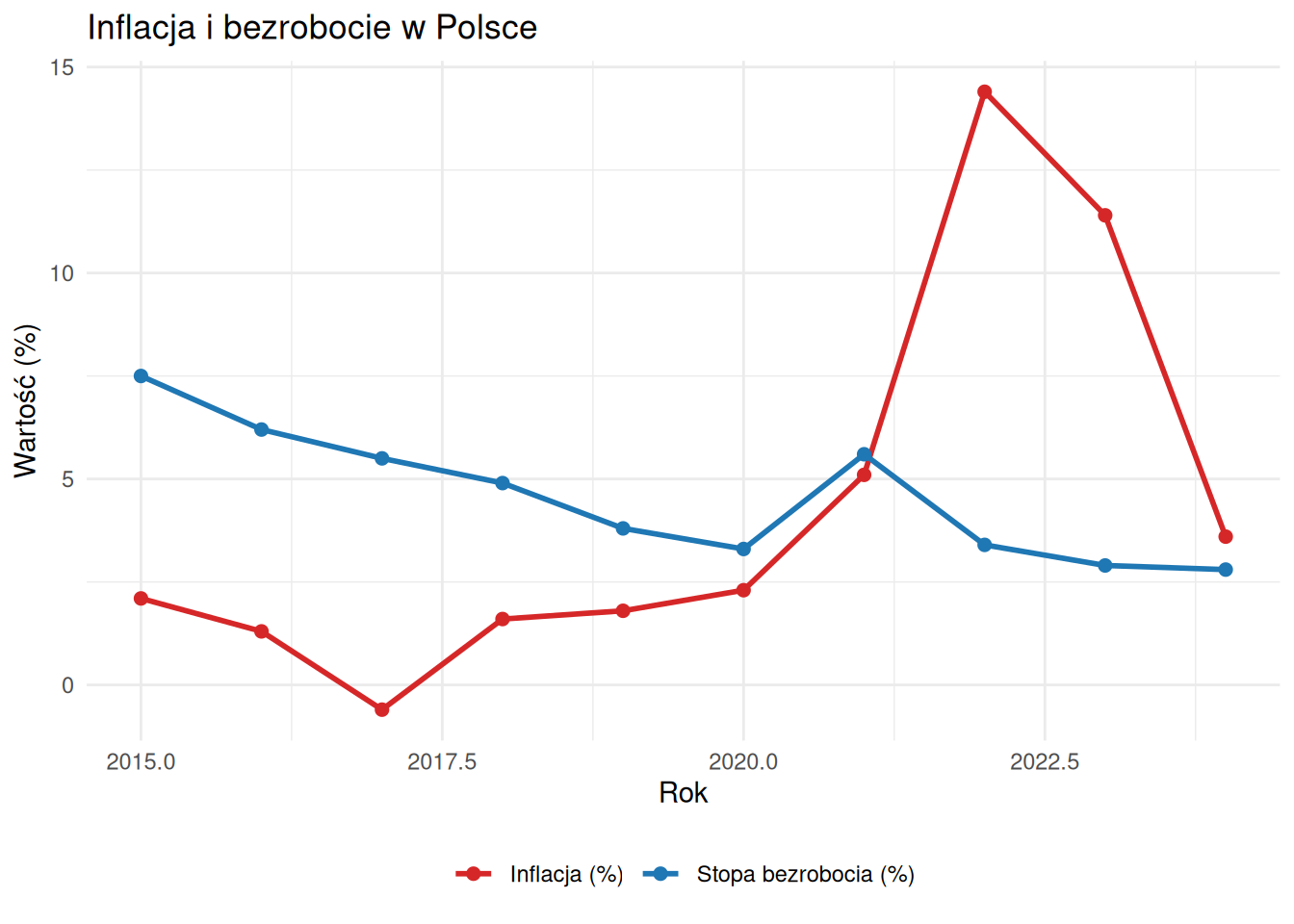
# Dwie linie — reshape danych do formatu długiego library (tidyr)<- dane_ekon |> select (rok, inflacja, stopa_bezrob) |> pivot_longer (cols = - rok, names_to = "wskaznik" , values_to = "wartosc" )ggplot (dane_dlugi, aes (x = rok, y = wartosc, color = wskaznik)) + geom_line (linewidth = 1 ) + geom_point (size = 2 ) + scale_color_manual (values = c ("inflacja" = "#d62728" , "stopa_bezrob" = "#1f77b4" ),labels = c ("Inflacja (%)" , "Stopa bezrobocia (%)" )+ labs (title = "Inflacja i bezrobocie w Polsce" ,x = "Rok" , y = "Wartość (%)" , color = NULL ) + theme_minimal () + theme (legend.position = "bottom" )
import pandas as pdimport matplotlib.pyplot as pltimport seaborn as sns"whitegrid" )= pd.DataFrame({"rok" : list (range (2015 , 2025 )),"PKB" : [1800 , 1862 , 1984 , 2120 , 2292 , 2330 , 2625 , 2780 , 2900 , 3070 ],"inflacja" : [2.1 , 1.3 , - 0.6 , 1.6 , 1.8 , 2.3 , 5.1 , 14.4 , 11.4 , 3.6 ],"stopa_bezrob" : [7.5 , 6.2 , 5.5 , 4.9 , 3.8 , 3.3 , 5.6 , 3.4 , 2.9 , 2.8 ]# Prosty wykres liniowy = plt.subplots(figsize= (9 , 5 ))"rok" ], dane_ekon["inflacja" ],= "steelblue" , linewidth= 2 , marker= "o" , markersize= 5 )"Inflacja w Polsce (2015–2024)" , fontsize= 14 )"Rok" )"Inflacja (%)" )True , alpha= 0.4 )# Dwie linie na jednym wykresie = plt.subplots(figsize= (9 , 5 ))"rok" ], dane_ekon["inflacja" ],= "#d62728" , linewidth= 2 , marker= "o" , markersize= 5 ,= "Inflacja (%)" )"rok" ], dane_ekon["stopa_bezrob" ],= "#1f77b4" , linewidth= 2 , marker= "s" , markersize= 5 ,= "Stopa bezrobocia (%)" )"Inflacja i bezrobocie w Polsce" , fontsize= 14 )"Rok" )"Wartość (%)" )True , alpha= 0.4 )
Wykres słupkowy — porównanie kategorii
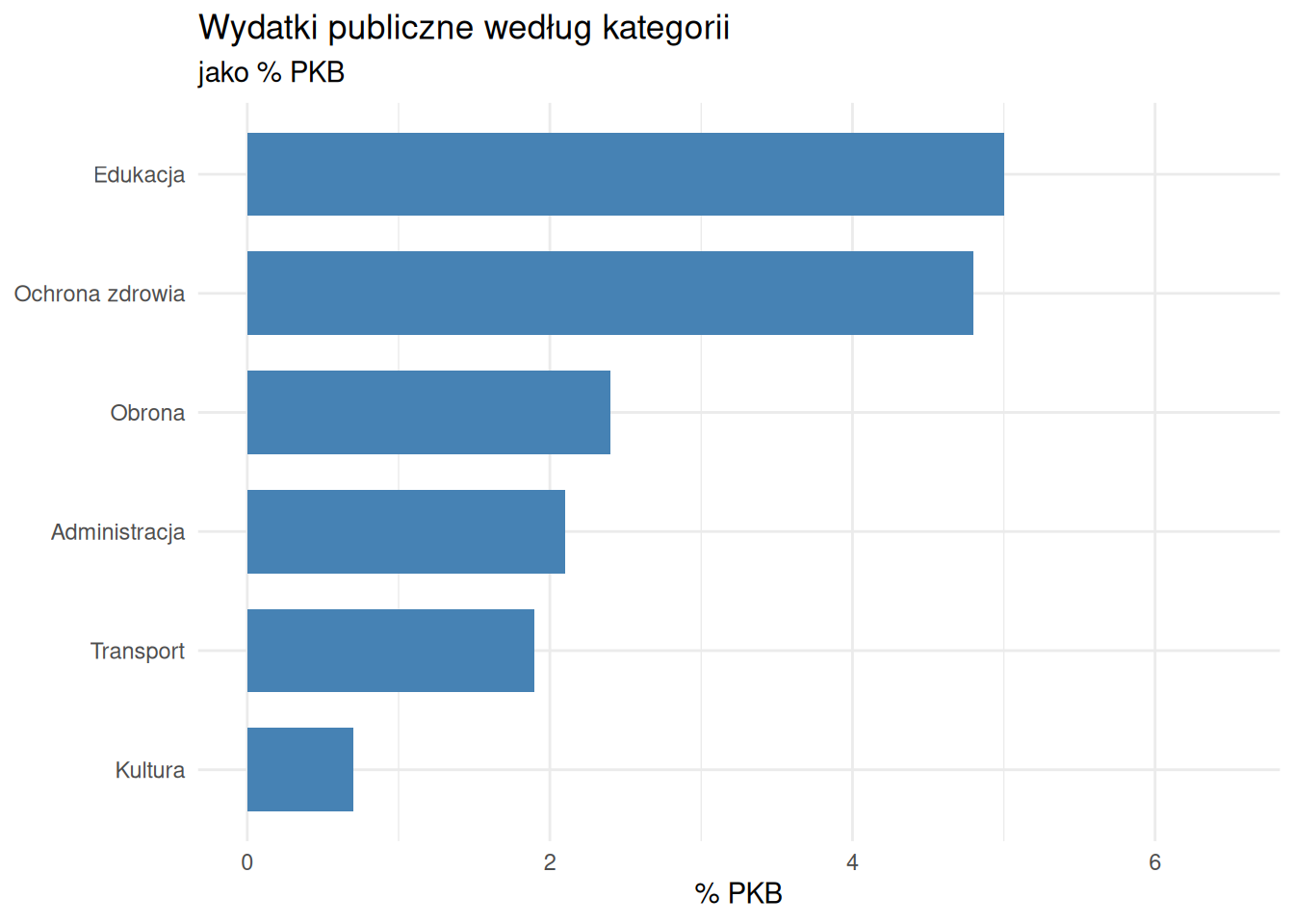
<- data.frame (kategoria = c ("Ochrona zdrowia" , "Edukacja" , "Obrona" ,"Transport" , "Kultura" , "Administracja" ),procent_PKB = c (4.8 , 5.0 , 2.4 , 1.9 , 0.7 , 2.1 )ggplot (wydatki, aes (x = reorder (kategoria, procent_PKB), y = procent_PKB)) + geom_col (fill = "steelblue" , width = 0.7 ) + coord_flip () + labs (title = "Wydatki publiczne według kategorii" ,subtitle = "jako % PKB" , x = NULL , y = "% PKB" ) + theme_minimal () + ylim (0 , 6.5 )
= pd.DataFrame({"kategoria" : ["Ochrona zdrowia" , "Edukacja" , "Obrona" ,"Transport" , "Kultura" , "Administracja" ],"procent_PKB" : [4.8 , 5.0 , 2.4 , 1.9 , 0.7 , 2.1 ]"procent_PKB" )= plt.subplots(figsize= (8 , 5 ))= ax.barh(wydatki["kategoria" ], wydatki["procent_PKB" ],= "steelblue" , height= 0.6 )"Wydatki publiczne według kategorii \n jako % PKB" , fontsize= 13 )"% PKB" )0 , 6.5 )= "x" , alpha= 0.4 )
Histogram i wykres gęstości — rozkład zmiennej
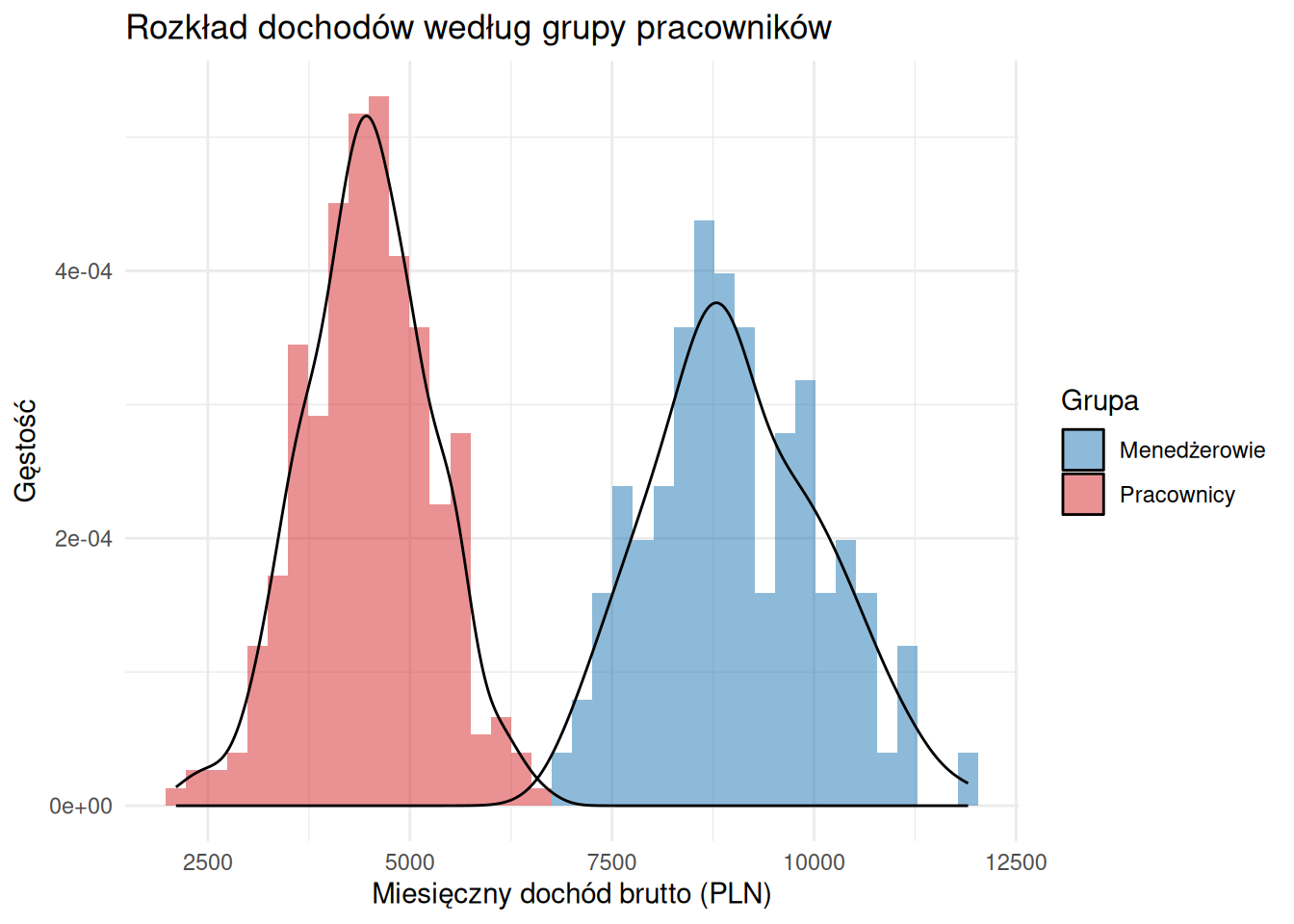
set.seed (42 )<- data.frame (dochod = c (rnorm (300 , mean = 4500 , sd = 800 ),rnorm (100 , mean = 9000 , sd = 1200 )),grupa = c (rep ("Pracownicy" , 300 ), rep ("Menedżerowie" , 100 ))ggplot (dochody, aes (x = dochod, fill = grupa)) + geom_histogram (aes (y = after_stat (density)),bins = 40 , alpha = 0.5 , position = "identity" ) + geom_density (alpha = 0 ) + scale_fill_manual (values = c ("#1f77b4" , "#d62728" )) + labs (title = "Rozkład dochodów według grupy pracowników" ,x = "Miesięczny dochód brutto (PLN)" , y = "Gęstość" , fill = "Grupa" ) + theme_minimal ()
import numpy as np42 )= pd.DataFrame({"dochod" : np.concatenate([4500 , 800 , 300 ),9000 , 1200 , 100 )"grupa" : ["Pracownicy" ] * 300 + ["Menedżerowie" ] * 100 = plt.subplots(figsize= (9 , 5 ))for grupa, kolor in [("Pracownicy" , "#1f77b4" ), ("Menedżerowie" , "#d62728" )]:= dochody[dochody["grupa" ] == grupa]["dochod" ]= 40 , density= True , alpha= 0.5 , color= kolor, label= grupa)= kolor, ax= ax, linewidth= 2 )"Rozkład dochodów według grupy pracowników" , fontsize= 13 )"Miesięczny dochód brutto (PLN)" )"Gęstość" )True , alpha= 0.3 )
Wykres punktowy — zależności między zmiennymi
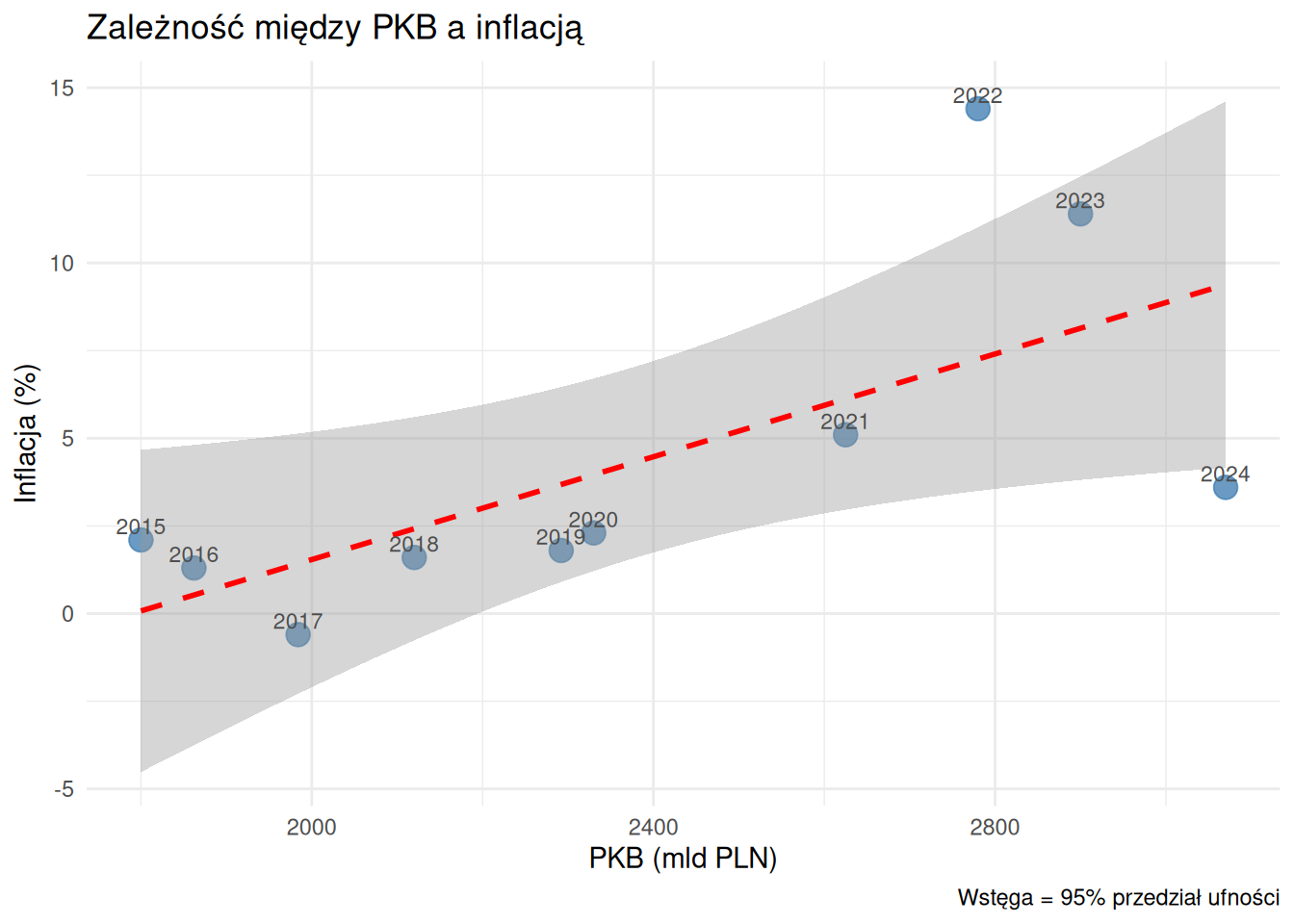
ggplot (dane_ekon, aes (x = PKB, y = inflacja, label = rok)) + geom_point (size = 4 , color = "steelblue" , alpha = 0.8 ) + geom_smooth (method = "lm" , se = TRUE ,color = "red" , linetype = "dashed" ) + geom_text (nudge_y = 0.4 , size = 3 , color = "gray30" ) + labs (title = "Zależność między PKB a inflacją" ,x = "PKB (mld PLN)" ,y = "Inflacja (%)" ,caption = "Wstęga = 95% przedział ufności" ) + theme_minimal ()
= plt.subplots(figsize= (8 , 5 ))"PKB" ], dane_ekon["inflacja" ],= 80 , color= "steelblue" , alpha= 0.8 , zorder= 5 )for _, row in dane_ekon.iterrows():str (int (row["rok" ])),"PKB" ], row["inflacja" ]),= "offset points" , xytext= (5 , 5 ),= 8 , color= "gray" )= np.polyfit(dane_ekon["PKB" ], dane_ekon["inflacja" ], 1 )= np.poly1d(z)= np.linspace(dane_ekon["PKB" ].min (), dane_ekon["PKB" ].max (), 100 )"r--" , alpha= 0.7 , label= "Trend liniowy" )"Zależność między PKB a inflacją" , fontsize= 13 )"PKB (mld PLN)" )"Inflacja (%)" )True , alpha= 0.3 )